
https://docs.google.com/spreadsheets/d/11DAONRZ92ob0T0YRIT5KgU9vNeO28bYNvteu_-fbRV0/edit#gid=0
딥러닝 워크북
회귀 (mse) 온도,판매량,W,B,Loss,예측 (w*온도+b),예측 - 판매량,(예측 - 판매량)^2 21,42,1.969,0.526,0.036891,41.875,-0.125,0.015625 22,44,dLoss / dW,dLoss / dB,prevLoss,43.844,-0.156,0.024336 23,46,122.2291,5.2961,7.028832,45.813,-0.187,
docs.google.com
이곳에 있는 자료를 보고 공부했다.
dt만큼 W와 B를 움직여보면서
loss 값이 커지는지, 작아지는지 확인하고(우리는 작아지는 방향으로 계산해야 한다.)
그 상황에 따라서 다음 W와 B가 결정된다.

점점 loss가 작아지도록 한 모습이다.

아이리스에 대한 데이터가 다음과 같이 있다.
품종이 종속변수가 될거다.
근데 종속변수가 전과 달리 숫자가 아닌 범주형 데이터 이다.

그럼 우리는 분류 모델을 만들어야 겠다.
범주형이니까!

전체 코드를 보면 저번 레모네이드 문제랑 조금 다른 부분을 볼수있다.
get_dummies 저것도 처음 보고
activation 도 전엔 없었던 것 같다.
하나씩 천천히 보자.
원핫인코딩

전처럼 이렇게 식을 세운다고 치자.
근데 결과가 범주형 데이터인데 y는 값으로 나오겠지.
이걸 어떻게 받아들여야 할까- 하는거다.
우리는 범주형인 종속변수를 수식에 사용할 수 있는 형태로 바꾸어 줄거다.

이렇게 범주형 데이터를 0아니면 1이라는 데이터로 나타내 줄수 있는데
이걸 원핫인코딩(onehot-encoding)이라고 한다.
(전에 딥러닝 스터디 때 배웠던 걸 다시 돌아가서 참고해보자~)

일단 처음엔 학습할 데이터를 불러온다.
그리고 만약 원핫인코딩을 하고싶다면 저 pd.get_dummies 를 써주면 되는데
판다스에서 지원해준다.
저걸 쓰면 데이터중에 범주형 데이터에 해당하는 것들을 0/1 데이터로 만들어 준다.

그러면 독립변수가 4개, 종속변수가 3개가 되었다고 할 수 있겠다.
식을 세운다면 다음과 같겠지.

이번엔 모델의 구조를 만들 차례다.
softmax 란 뭘까?

우리는 확률을 나타내어 분류를 나타낸다.
이럴 때 쓰는 도구가 sigmoid와 softmax 이다.
여기서는 softmax 만 사용할 거다.

다음과 같이
setosa일확률은 0.7이고 virginica 일 확률은 0.3이다.. 라는 식으로 보여진다.
softmax를 사용하면 0과 1 사이의 값으로 볼 수 있다.

전에는 아무것도 안썼지만(회귀모델)
저 f를 방금 문제에서는 softmax 로 쓴거구,
예전 문제에서는 회귀모델로 쓴거다.
이런걸 활성화 함수라고 한다.

학습이 제대로 되려면 문제 유형에 맞게 loss 를 맞춰주어야 한다.
분류에 사용하는 loss 는 crossentropy 라고 알아두고,
회귀에 사용하는 loss 는 mse 라고 알아두자.
어쨌든 모델을 만들고 보자. 결과를 출력할 때 정확도도 같이 보고 싶다면 저렇게 accuracy를 추가해주면 된다.

google colab 에서 실습을 해보자

필요한 라이브러리를 임포트 해줬고
데이터를불러와 줬다.
아이리스라는 변수에 넣어주고
한번 데이터 5개를 출력해주자.
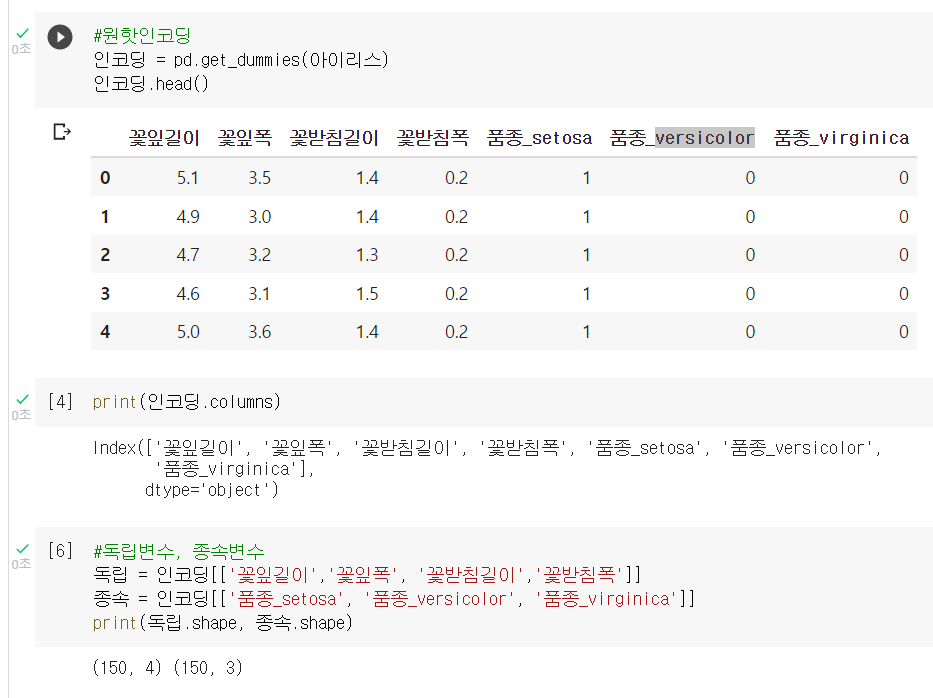
onehot encoding 을 해주기 위해서 판다스에서 제공하는 저 pd.get_dummies를 써주자
그러면 범주형 데이터가 저렇게 3개의 종속변수로 나누어진다.
이제 독립변수와 종속변수도 지정해줬다.
shape를 한번 출력해주고.

모델의 구조를 본격적으로 만들어줬다.
softmax 활성화함수 써주었고
이건 분류 문제니까 crossentropy를 써줬다. 정확도도 보고 싶어서 accuracy 를 추가해줬다.
10번 학습시켰는데 loss가 점점 떨어지는 게 보인다.
200번을 더 학습시켜줬다.


정확도가 90프로 대로 높아지고 loss 도 적어졌다.

한번 독립변수 데이터를 모델에 넣어서 결과를 확인했다.
setosa 일 확률이 89 80 97... 등등으로 나온다.
정답을 확인해보기위해 종속변수를 출력해보았다.
정답이 setosa로 맞았다.

가중치는 다음과 같다.
참고 : 생활코딩