
수업시간에 과제를 구현하면서 빅 엔디안과 리틀엔디안에 관련해서 이해해야하는 부분이 있었다.
https://www.save-editor.com/tools/wse_hex.html
HEX & LITTLE ENDIAN CONVERTER - SAVE-EDITOR.com
www.save-editor.com
여긴 내가 잘 구현했는지 확인해보기 위해서 이용했던 엔디안 변환 사이트
bit 와 byte
일단 컴퓨터는 모든 데이터를 2진수로 표현하고 처리한다.
bit 는 데이터의 최소 단위이다. 0아니면 1만 저장이 가능하다.
byte는 이러한 bit가 8개 모여서 구성된다. 이건 한 문자를 표현할 수 있는 최소 단위이다.
컴퓨터는 데이터를 메모리에 저장할 때 byte 단위로 나누어서 저장을 한다.
보통 컴퓨터가 저장하는 데이터는 32bit(4byte) 나 64bit(8byte)이다.
이 바이트를 저장하는데 순서가 필요할 것이다.
이 순서에 따라서 2개의 방식으로 나눌 수 있다.
빅엔디안과 리틀엔디안이다.
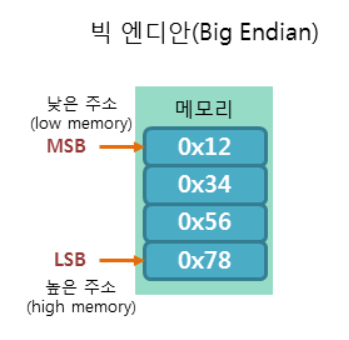
빅 엔디안(Big endian)
빅 엔디안은
낮은 주소에 높은 바이트부터 저장하는 방식이다.
우리가 평소에 숫자를 사용하는 선형방식과 같은 방식이라고 할 수 있다.
이해하기 쉽고, 저장된 순서 그대로 읽을 수 있다.
예를 들어 0x12345678 이라는 데이터가 있다.
이 데이터는 32bit 크기의 정수이다.
이 정수는 1byte * 4개 로 구성될 수 있다.
0x12, 0x34, 0x56, 0x78
이 4개의 byte를 빅 엔디안 방식으로 메모리에 저장하면 다음과 같다.
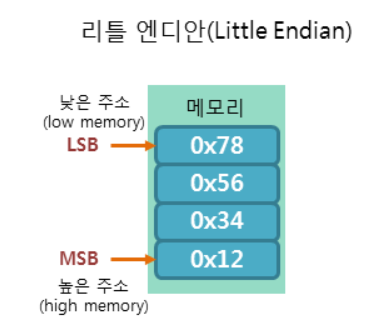
리틀 엔디안(Little Endian)
리틀 엔디안 방식은 빅 엔디안 방식과 반대다.
낮은 주소에 낮은 바이트부터 저장하는 방식이다.
(대부분의 인텔 cpu 계열에서는 이 방식으로 데이터를 저장한다.)
위에서 예로 들었던 0x12345678 을 예로 든다면
리틀엔디안에서는 아래와 같이 메모리에 저장된다.
뭐가 더 우수하다고 할 수는 없다.
데이터를 어떻게 나누어 저장하는가의 차이일 뿐이기 때문이다.
하지만 물리적으로 데이터를 조작하거나 산술 연산을 수행할 때에는 리틀엔디안이 더 효율적이다.
하지만 데이터의 각 byte를 배열처럼 취급할 때에는 빅 엔디안이 적합하다.
덧붙여서, 네트워크를 통해서 데이터를 전송할 때에는 빅 엔디안 방식이 사용된다.
다음은 엔디안을 변환시키는 함수를 c언어로 구현한 코드이다.
//change endian
unsigned int invertEndian(unsigned int inVal) {
int result;
unsigned char bytes[4];
bytes[0] = (unsigned char)((inVal >> 24) & 0xff);
bytes[1] = (unsigned char)((inVal >> 16) & 0xff);
bytes[2] = (unsigned char)((inVal >> 8) & 0xff);
bytes[3] = (unsigned char)((inVal >> 0) & 0xff);
result = ((int)bytes[0] << 0) |
((int)bytes[1] << 8) |
((int)bytes[2] << 16) |
((int)bytes[3] << 24);
return result;
}수업시간에 과제를 구현하면서 빅 엔디안과 리틀엔디안에 관련해서 이해해야하는 부분이 있었다.
https://www.save-editor.com/tools/wse_hex.html
HEX & LITTLE ENDIAN CONVERTER - SAVE-EDITOR.com
www.save-editor.com
여긴 내가 잘 구현했는지 확인해보기 위해서 이용했던 엔디안 변환 사이트
bit 와 byte
일단 컴퓨터는 모든 데이터를 2진수로 표현하고 처리한다.
bit 는 데이터의 최소 단위이다. 0아니면 1만 저장이 가능하다.
byte는 이러한 bit가 8개 모여서 구성된다. 이건 한 문자를 표현할 수 있는 최소 단위이다.
컴퓨터는 데이터를 메모리에 저장할 때 byte 단위로 나누어서 저장을 한다.
보통 컴퓨터가 저장하는 데이터는 32bit(4byte) 나 64bit(8byte)이다.
이 바이트를 저장하는데 순서가 필요할 것이다.
이 순서에 따라서 2개의 방식으로 나눌 수 있다.
빅엔디안과 리틀엔디안이다.
빅 엔디안(Big endian)
빅 엔디안은
낮은 주소에 높은 바이트부터 저장하는 방식이다.
우리가 평소에 숫자를 사용하는 선형방식과 같은 방식이라고 할 수 있다.
이해하기 쉽고, 저장된 순서 그대로 읽을 수 있다.
예를 들어 0x12345678 이라는 데이터가 있다.
이 데이터는 32bit 크기의 정수이다.
이 정수는 1byte * 4개 로 구성될 수 있다.
0x12, 0x34, 0x56, 0x78
이 4개의 byte를 빅 엔디안 방식으로 메모리에 저장하면 다음과 같다.
리틀 엔디안(Little Endian)
리틀 엔디안 방식은 빅 엔디안 방식과 반대다.
낮은 주소에 낮은 바이트부터 저장하는 방식이다.
(대부분의 인텔 cpu 계열에서는 이 방식으로 데이터를 저장한다.)
위에서 예로 들었던 0x12345678 을 예로 든다면
리틀엔디안에서는 아래와 같이 메모리에 저장된다.
뭐가 더 우수하다고 할 수는 없다.
데이터를 어떻게 나누어 저장하는가의 차이일 뿐이기 때문이다.
하지만 물리적으로 데이터를 조작하거나 산술 연산을 수행할 때에는 리틀엔디안이 더 효율적이다.
하지만 데이터의 각 byte를 배열처럼 취급할 때에는 빅 엔디안이 적합하다.
덧붙여서, 네트워크를 통해서 데이터를 전송할 때에는 빅 엔디안 방식이 사용된다.
다음은 엔디안을 변환시키는 함수를 c언어로 구현한 코드이다.
//change endian unsigned int invertEndian(unsigned int inVal) { int result; unsigned char bytes[4]; bytes[0] = (unsigned char)((inVal >> 24) & 0xff); bytes[1] = (unsigned char)((inVal >> 16) & 0xff); bytes[2] = (unsigned char)((inVal >> 8) & 0xff); bytes[3] = (unsigned char)((inVal >> 0) & 0xff); result = ((int)bytes[0] << 0) | ((int)bytes[1] << 8) | ((int)bytes[2] << 16) | ((int)bytes[3] << 24); return result; }