
multi-variable 을 사용할 수 있으면 실제로 가지고 있는 데이터에 적용해볼수 있다.

다음과 같은 데이터가 있다. 마지막 기말고사 시험인 Y를 예측하는 모델을 만들 거다
x가 많을 수록 예측을 잘할 수 있겠지?
hypothesis를 자연스럽게 세워보자

그러면 마찬가지로 cost는

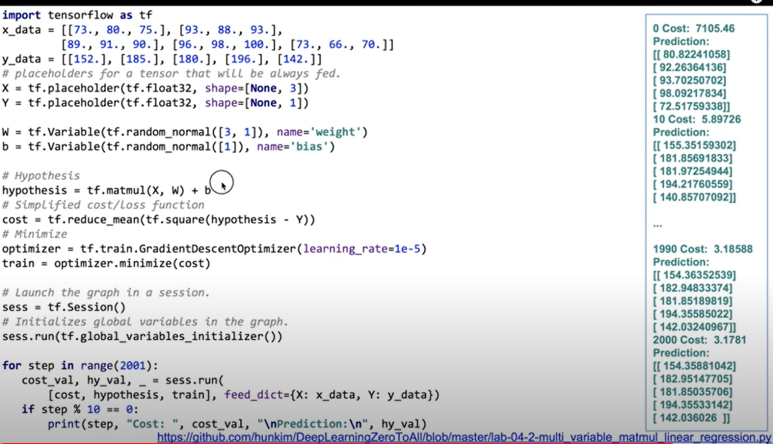
오른쪽에 결과를 보면 cost가 상당히 높다가 4로 낮게 떨어지는 걸 볼 수 있다
2000 Cost 일때를 보면 prediction의 값이 왼쪽 위에 있는 y_data(기대하는 값)와 유사하다.
수렴한다고 볼 수 있겠다.
근데 윗 부분이 너무 복잡하다. 이런방법은 이제 사용하지 않는다.
이걸 대체할 것이 matrix이다.
matrix를 구현해보자

x_data를 위처럼 묶어서 써줘도 된다.
그담에 placeholder를 만들어주고,,
shape 안에 None이라는 거는 저 x_data안에 있는걸 n으로 둔다면 tensorflow는 그걸 None이라고 표현하기 때문이다.(내가 원하는 만큼 데이터를 줄수 있다는 뜻)
단 각 instance가 가지는 element는 3개라고 정해져있다.
이전에 했던것처럼 optimizer,,, session,,, 다 똑같다.
오른쪽 결과를 보면 아까랑 똑같다.
대신 구현할 때 표현이 쉬워진다는 것!
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
x_data = [[73.,80.,75.], [93.,88.,93.], [89.,91.,90.],[96.,98.,100.],[73.,66.,70.]]
y_data = [[152.],
[185.],
[180.],
[196.],
[142.]]
X = tf.placeholder(tf.float32, shape=[None, 3])
Y = tf.placeholder(tf.float32, shape=[None, 1])
W = tf.Variable(tf.random_normal([3,1]), name = 'weight')
b = tf.Variable(tf.random_normal([1]), name = 'bias')
hypothesis = tf.matmul(X,W) + b
cost = tf.reduce_mean(tf.square(hypothesis - Y))
optimizer = tf.train.GradientDescentOptimizer(learning_rate = 1e-5)
train = optimizer.minimize(cost)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for step in range(2001):
cost_val, hy_val, _ = sess.run(
[cost, hypothesis, train], feed_dict={X: x_data, Y: y_data})
if step % 10 == 0:
print(step, "Cost: ", cost_val, "\nPrediction:\n", hy_val)colab에서 실습을 해보았다.
0 Cost: 71553.25
Prediction:
[[ -90.45916]
[ -97.33355]
[-101.58188]
[-111.90065]
[ -70.54739]]
10 Cost: 13.334216
Prediction:
[[146.16324]
[187.04333]
[178.63283]
[193.24486]
[146.35524]]
.
.
.
1990 Cost: 4.591146
Prediction:
[[148.95015]
[186.48372]
[180.11139]
[194.6693 ]
[145.10959]]
2000 Cost: 4.5684137
Prediction:
[[148.95798]
[186.47829]
[180.11375]
[194.67122]
[145.1023 ]]결과는 이렇게 나왔다.
이거 실습한걸 깃허브에 저장하려고 하는데 gist로 사본 저장이 있고 그냥 사본저장이 있길래
https://zzsza.github.io/data/2018/08/30/google-colab/
Google Colab 사용하기
Google의 Colab 사용법에 대해 정리한 글입니다 이 글은 계속 업데이트 될 예정입니다! 목차 UI 상단 설정 구글 드라이브와 Colab 연동 구글 드라이브와 로컬 연동 Tensorflow 2.0 설치하기 PyTorch 사용하기
zzsza.github.io
여기서 찾아봤는데
gist로 사본저장하는 건 gist라는 거에 secret으로 저장하는 거라고한다(처음에 연동설정이 필요하다)
나는 그냥 레포지터리의 특정 브랜치에 저장하려고 하는거니까 그냥 사본저장을 하면 되겠다!