
참고 영상
이번엔 데이터들을 실제 파일에서 읽어오는걸 해보려고 한다.
데이터가 많아지면서 데이터들을 소스코드에 일일이 다 써넣기가 복잡해진다.

읽어오려면 어떻게 할까?
numpy에 있는 loadtxt라는 함수를 이용하면 된다.
loadtxt(파일이름, ','로 나누겠다, 데이터 타입)
단점이 있다면 이 데이터들의 타입이 다 같아야 하겠다.
데이터를 가져올때 보니까 슬라이싱을 이용한다.

슬라이싱은 파이썬 리스트의 강력한 기능이다. 이미 알고있지!
잘 알아둬야한다.

numpy로 가면서 더 막강한 인덱싱와 슬라이싱이 가능해진다.
2차원 array를 잘봐두자 (오른쪽!!)
그래서 다시 아까로 돌아가면

x_data의 슬라이싱 의미는 전체를 다 가져올 건데, 마지막 1개의 원소를 뺀 리스트들을 가져와라 ->x_data로 할거다
라는 의미이다
같은 방법으로 y_data는 마지막 끝에있는 원소 1개만 다 가져오겠다 라는 의미이다.
여기까지 했다면 그 다음은 이전과 유사하다

w를 보면 [3,1]인것 확인 할 수 있겠다 (3개 X가 들어와서 1개 Y로 나가는 거니까)
b는 출력값 Y 1개 니까 [1] 일테고!
오른쪽 박스에 써져 있는 것중에 #Ask my score 이부분은 뭐냐면
나중에는 내가 내 점수 3개를 입력해서 '내가 기말고사 점수를 몇점 받을 수 있을까 예측해줘!' 를 할 수 있다는 거다
아니면 친구의 점수 데이터를 동시에 2개 입력할 수도 있겠지(그 아래 코드처럼)

실제로 결과도 저렇게 나오면서 점수를 예측해준다!
만약에 파일이 굉장히 크다던지해서 메모리에 한번에 올리기가 힘이 들수 있다
이런경우에는 numpy로 하려고하면 힘들 수 있다.
이런 경우를 대비해 tensorflow에서는 queue runner라는 것을 만들어뒀다.
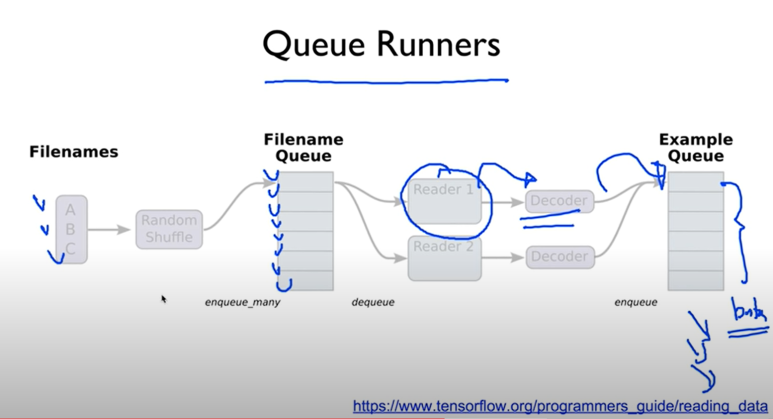
결론은 한꺼번에 다 갖다 쓰지 않고 저기 queue에다가 쌓아뒀다가 몇개씩 빼다가 쓴다는 이야기
->큰 데이터를 써야할때 유용하다
근데 좀 복잡해보인다.
차근차근 봐보자
첫번째 스텝

우리가 가지고 있는 파일들의 리스트를 만들어 준다.
shuffle은 shuffle할건지
name은 queue의 이름을 정하는 것
두번째 스텝

파일을 읽어올 reader를 정의해준다.
textline으로 읽을거라 저렇게 TextLineReader로 해준것같다.(다른 reader들도 있다고 한다)
그리고 key, value로 나누어 읽겠습니다~ 하는것.
그럼 우리는 이제 value를 읽어왔겠지?

읽어온 value를 어떻게 이해할 것인가..
decode_csv라는 걸로 해독할거다.
record_defaults 는 각각의 field에 해당하는 데이터들이 어떤 데이터 타입인가를 정해줄 수 있다.
지금은 [0.] 이런 데이터 타입이다 하고 정의 해준거다. float이니까 우리 데이터는!
이제 batch라는 걸 이용할건데 아래를 보자

저 batch라는 건 데이터를 뽑아올수있도록 일종의 펌프 역할을 한다. 그래서 읽어올 수 있는거다.
노드이름은 train_x_batch, train_y_batch 라고 정해주었고,
batch_size를 10으로 해줬는데, 저건 한번에 10개씩 데이터를 가져와라! 라는 의미다.
그 다음엔 session을 실행한다.
coord 어쩌구 부터 있는건.. 그냥 통상적으로 저렇게 쓴다고 한다. 복잡한 부분은 tensorflow가 다 알아서 해준다구. 복잡해보이지만 일반적으로 이렇게 하니까 그대로 따라서 하면 된다.
나중에 x_batch 나 y_batch같은건 feed-dict 를 통해 값을 넘겨주면 되겠지 우리의 모델에 맞게!

제대로 구현하면 이렇게 되겠다.
결과는 이전에 numpy로 했던 것과 똑같이 나온다.
batch의 순서가 shuffle 되면 좋겠을 경우도 있을 수 있지
그럴땐 shuffle_batch를 쓰거나 다른 함수들을 사용해도 좋다고 한다.
실습을 해보려고 한다.
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
filename_queue = tf.train.string_input_producer(
['data-01-test-score.csv'], shuffle=False, name='filename_queue')
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
record_defaults = [[0.], [0.], [0.], [0.]]
xy = tf.decode_csv(value, record_defaults=record_defaults)
train_x_batch, train_y_batch = \
tf.train.batch([xy[0:-1], xy[-1:]], batch_size=10)
X = tf.placeholder(tf.float32, shape=[None, 3])
Y = tf.placeholder(tf.float32, shape=[None, 1])
W = tf.Variable(tf.random_normal([3, 1]), name='weight')
b = tf.Variable(tf.random_normal([1]), name='bias')
hypothesis = tf.matmul(X, W) + b
cost = tf.reduce_mean(tf.square(hypothesis - Y))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1e-5)
train = optimizer.minimize(cost)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for step in range(2001):
x_batch, y_batch = sess.run([train_x_batch, train_y_batch])
cost_val, hy_val, _ = sess.run(
[cost, hypothesis, train], feed_dict={X: x_batch, Y: y_batch})
if step % 10 == 0:
print(step, "Cost: ", cost_val, "\nPrediction:\n", hy_val)
coord.request_stop()
coord.join(threads)
# Ask my score
print("Your score will be ",
sess.run(hypothesis, feed_dict={X: [[100, 70, 101]]}))
print("Other scores will be ",
sess.run(hypothesis, feed_dict={X: [[60, 70, 110], [90, 100, 80]]}))근데 csv 파일이 뭐지, 메모장으로 만들 수 있는건가? 검색해보았다.

구글은 친절하다.

시키는 대로 했다.
이 파일을 colab에서 불러오려면 어떻게 해야하지?
1. 구글 드라이브에 올려서 불러올수있다
2. url 에서 불러올 수 있다
3. colab 에 파일을 직접 업로드 할 수 있다.
나는 3번째 방법으로 하고 싶다.
from google.colab import files
uploaded = files.upload()
이 코드를 추가하면 파일을 선택할 수 있다고 한다.

오 진짜 결과창에 저런게 떴다.
아 근데 올렸는데도 오류가 뜬다..
결국 구글 드라이브에 마운트? 하는 방법으로 시도 했다
안된다..
하.....30분째 데이터 불러오는 것만 하고 있다
나중에 다시 해봐야지 아놔,,