
참고영상
logistic regression 을 tensorflow를 통해 구현해보는 시간
맨 처음부터!
일단 우리가 가지고 있는 데이터는?

x_data 안에 들어가있는 각각 리스트들은 하나의 인스턴스를 말할거다
그리고 y_data의 결과값은 0 아니면 1로만 나온다고 하자.
그 다음 feed-dict 를 사용하기 위해선 placeholder를 사용해야 한다.
X 와 Y를 만들었다.
shape에 주의 해야 한다.
더 많은 x_data , y_data를 줄수도 있으니 None(n)으로 설정해 둔거고
X에서 shape을 2로 둔 이유는 x1, x2 이렇게 변수가 2개이기 때문이고.
Y는 y_data가 1개이기 때문에 shape 에 1이라고 쓴거고

그런 다음엔 W와 b를 써준다
우리는 matrix 곱셈을 할거다 -> Weight의 shape에 신경을 써야한다
matrix(X,W) 을 하겠지
W의 shape을 쓸때 2인건 X의 2번째 숫자랑 맞춰준거다 --> [None, 2]* [2 ,1]
1인 이유는 나가는값이 1개이기 때문이다.
b(bias)는 나가는 값이 1개 이니까 이것도 1이라고 써주면 된다.
그 아래 코드를 보자
tf.matmul(X,W) + b
이 부분은
WX + b를 의미한다
이걸 sigmoid에 넣어주는 거다
이걸 직접 구현하고 싶다! 하면 주석으로 써져있는 코드를 쓰면 되겠다.
그 아래 cost 부분을 보자
reduce_mean 이부분은 1/m 시그마 (평균내는 식)
그 아래 부분
cost 좀 minimize 해줘! 하면
train이 w을 조절해주겠지
만약에 값이 0.8로 나오면 1이랑 가까우니까 Pass라고 고려할거고
0.1로 나오면 0이랑 가까우니까 Fail이라고 생각할거다
이 기준은 아마 0.5가 되겠지!
이 결과값을 0.5를 기준으로 판단하고
tensorflow에서 float32로 casting 을 하면
True는 1, False는 0으로 나오게 된다.
predict에 이걸 저장하자
우리가 예측한 값 predicted 와 주어진 Y의 값이 똑같은지 확인하고(equal)
cast를 해서 0이나 1로 나오게 한다
이 값들을 평균을 낸다
이게 accuracy 이다

학습하는 모델은 이전과 동일하다
200번 마다 한번씩 출력하도록 하자
전체~~~~~~ 코드를 보자
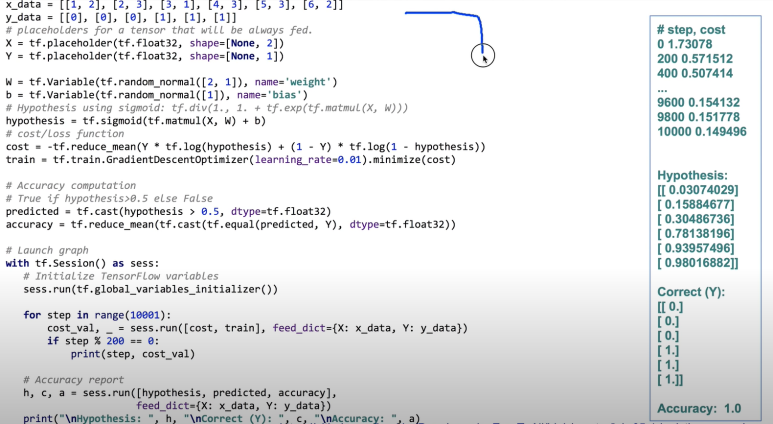
코드는 이전과 동일하니 출력된 결과를 보자
step이 0부터 늘어나는데 cost가 점점 작아진다
hypothesis를 보자
저 각각의 숫자들을 0이랑 1중에 가까운 수로 가도록하면 우리가 가지고 있는 y_data와 같다
실제 Y값과 똑같네!
실제 데이터에 적용해보자

당뇨병을 연구하는 자료
맨 오른쪽에 있는게 y_data가 되겠다

전체 코드는 이러하다
shape을 주의해야겠다
x의 값이 8개니까, 이전과 다르게.
accuracy를 보면 76프로 정도의 정확도를 가진다는 걸 알수 있겠다