
머신러닝 야학 3기에 참가신청을 했다.(21.7.19)
저번에 딥러닝을 맛 봤었는데 다시 한번 다지고 싶어서!

커리 큘럼은 이렇게 되는데 머신러닝1은 빨리 할 수 있을 것 같아서
머신러닝1 듣고 텐서플로우를 들으려고 한다.
일단 오늘은 머신러닝1 을 들으며 정리하겠다.
https://teachablemachine.withgoogle.com/
Teachable Machine
Train a computer to recognize your own images, sounds, & poses. A fast, easy way to create machine learning models for your sites, apps, and more – no expertise or coding required.
teachablemachine.withgoogle.com
이 사이트에 접속해보자

이미지 프로젝트로 들어가면 이렇게 뜨는데
나는 손을 브이하는 이미지와 손바닥을 쫙 편 이미지를 두 클래스에 각각 입력했다.

모델을 학습시키고 나서 손을 이리저리 움직여 봤더니
정말 손바닥을 폈을땐 손펴기 100%로 나오고
손브이를 할때에는 손브이가 100%가 나온다
애매한 손모양을 했을땐 확률이 반반으로 되기도 한다.
이런걸 기계 학습(Machine Learning) 이라고 할 수 있겠다.
모델 내보내기를 클릭해봤는데 코드파일을 다운받을 수도 있는 것 같다. 신기하다.
다운받아서 압축을 풀어보면
metadata.json
model.json
weights.bin
이렇게 3개의 파일이 나온다.
모델 (Model)
머신러닝을 만든 사람들은 경험에 의한 판단력을 모델이라고 부르기로 했다.
그리고 이 모델을 만드는 과정을 학습(Learning)이라고 부르기로 했다.

학습이 잘되면 좋은 모델을 얻을 수 있고
이 좋은 모델을 가지고 좋은 추측을 할 수 있다.
표
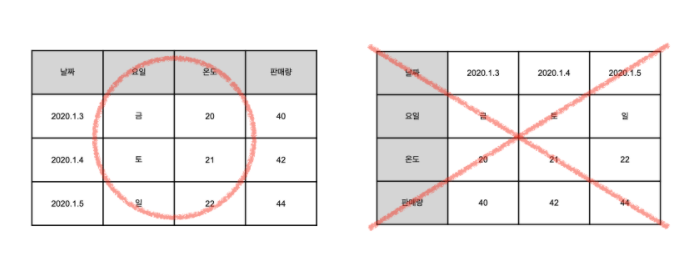
데이터 산업에서는 왼쪽처럼 쓰자고 약속을 했다.
표는 데이터들의 모임, 즉 데이터 셋(data set) 으로 불린다.
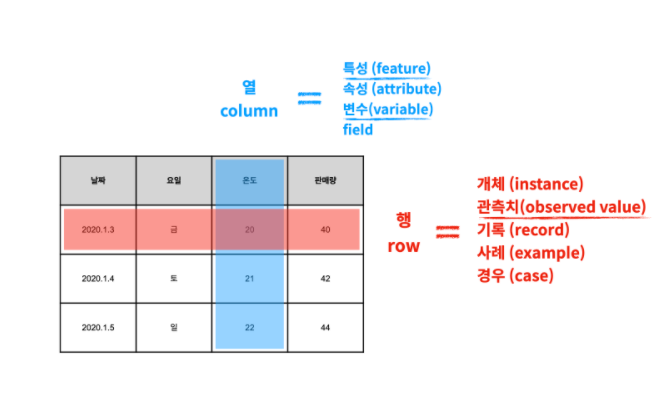
행은 그 하루를 나타내고
열은 그 하루의 특징을 나타내고 있다.
데이터를 표에 넣는 것 뿐만 아니라 의미있는 정보를 뽑아낼 수 있어야 한다.
독립변수와 종속변수라는 말의 의미를 이해해보자.

독립변수 = 원인이 되는 열
종속변수 = 결과가 되는 열

저 두 열은 상관있는 특성이다.
상관관계가 있다고 할 수 있다.
더 자세히 보면 인과관계가 있다고 할 수 있다.
온도는 원인이고 판매량은 결과이기 때문이다.

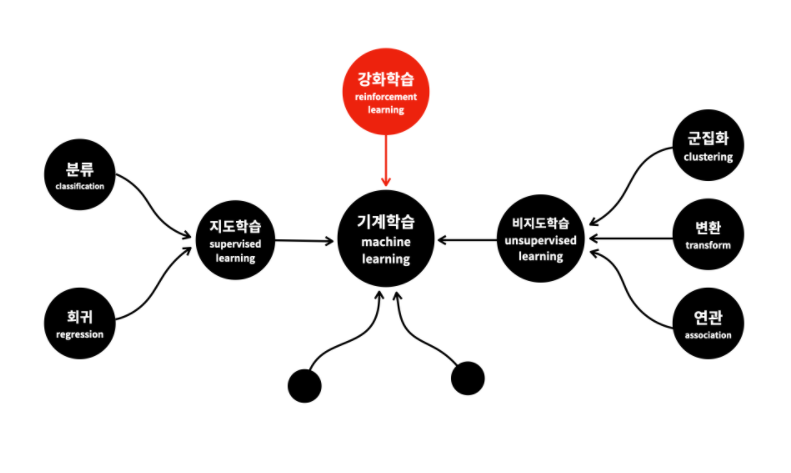
머신러닝의 분류

지도학습 : 데이터로 컴퓨터를 학습시켜서 모델을 만드는 방식
비지도학습 : 기계에게 데이터에 대한 통찰력을 부여하는 것. 정답을 알려주지 않아도 관찰을 통해 새로운 의미나 관계를 밝혀냄. (데이터의 성격을 파악하거나 데이터를 잘 정리정돈 하는 것에 사용됨)
강화학습 : 학습을 통해서 능력을 향상시킴
지도학습
지도 학습을 하기 위해서는 과거의 데이터가 필요.
그 데이터를 독립변수와 종속변수로 분리해야함.
독립변수와 종속변수의 관계를 학습시키면 컴퓨터는 그 관계를 설명할 수 있는 공식을 만들어냄.
그 공식을 '모델'이라고 부름
지도학습은 크게 회귀와 분류로 나뉨
회귀(Regression)
예측하고 싶은 종속변수가 숫자일때 보통 회귀를 사용함
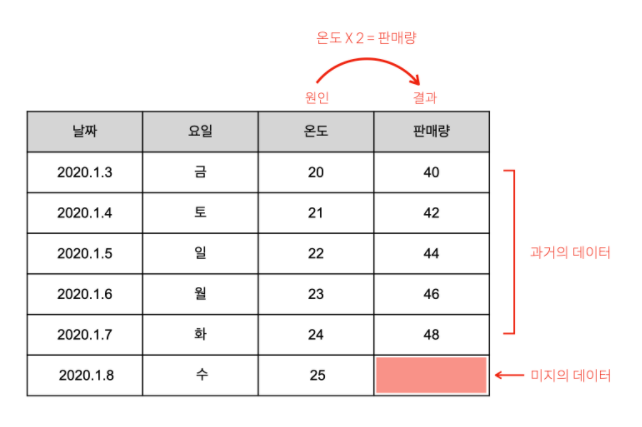
1월 8일에 판매량을 예측할때 그 데이터의 형태가 숫자이니 회귀를 사용해야겠다.
분류(Classification)
아까 손브이와 손펴기를 분류했었는데
이건 과거의 데이터를 가지고 배운다는 점에서 지도학습이다.
그런데 결과가 손브이 / 손펴기 이다. -> 숫자가 아니다
이럴 땐 분류라는 방법을 이용한다.
양적 데이터와 범주형 데이터
산업에서는 숫자라는 모호한 표현대신 양적 이라는 표현을 쓴다
(양적 데이터 = 숫자)
그리고 산업에서는 이름이라는 표현 대신 범주 라는 표현을 쓴다
(범주형 데이터 = 이름)

위 데이터는 양적 데이터 이며
종속변수가 양적 데이터면 회귀를 사용하면 된다
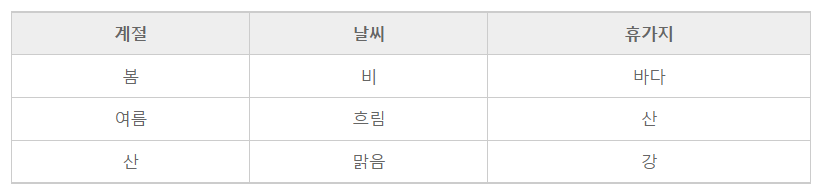
이 데이터는 범주형 데이터이고
종속변수가 범주형 데이터라면 분류를 사용하면 된다.
비지도 학습
비지도 학습의 사례로는
군집화와 연관 규칙이라는 것이 있다.
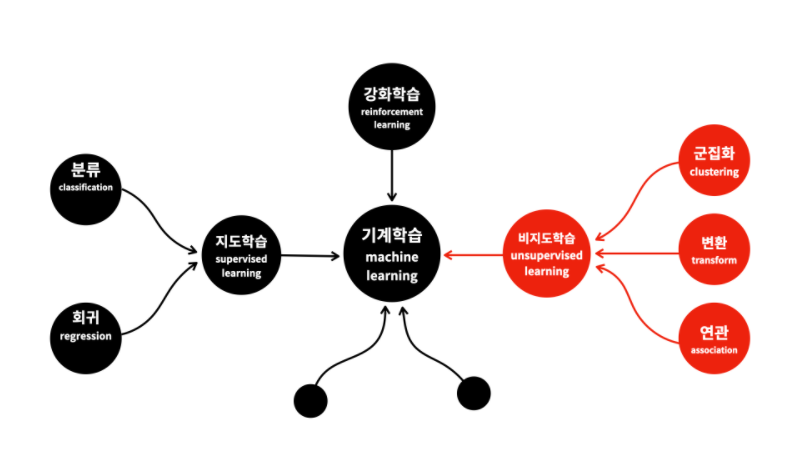
군집화(Clustering)
군집화랑 분류는 다른 개념이다.
비슷한 것들끼리 모아서 그룹으로 만드는 건 군집화이고
분류는 그 대상이 어떤 그룹에 속하는지 판단하는 것이다.
만약 배달 사업을 하는데 사용자가 전국에 1000만명이다.
100개의 배달본부를 오픈하려고 하는데 배치할 위치를 고민중이다.
이럴땐 1000만명이 적절히 분포되어 있는 100개의 그룹을 만들어야 한다.
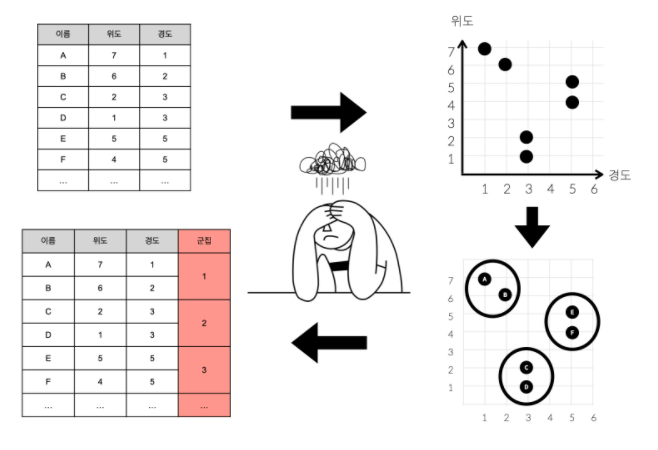
저 표의 행이 6개가 아니라 1000만개이면 계산하는게 불가능해질거다.

하지만 군집화라는 도구에 1000만개의 관측지(행)을 입력하고 100개의 클러스터가 필요하다고 알려주면 유사한 속성을 가진 관측지끼리 분류해서 총 100개의 클러스터를 만들어 줄거다.

결과를 표로 나타내면 다음과 같을거다.
군집화는 서로 가까운 관측치를 찾아주는 머신러닝의 기법이라고 할 수 있다.
(좌표상에서 가까운(데이터가 비슷한) 것을 붂어준다)
따라서 비슷한 행을 그룹핑 하는것 -> 군집화
연관규칙학습 Association rule learning
연관규칙학습은 서로 연관된 특징을 찾아내는 것이다.
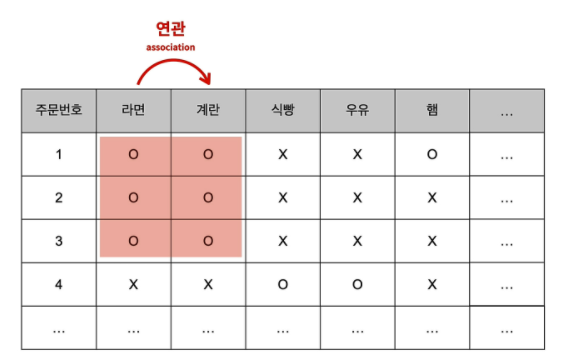
내가 쇼핑몰 사장인데
사용자들에게 구입한 품목과 연관된 상품을 추천해주고 싶다.
저 데이터를 보니 라면과 계란은 연관관계가 있는 것같다.
하지만 데이터가 1만개이고 사용자가 1000만명이면 힘들것같다. -> 이걸 해결하는게 연관규칙
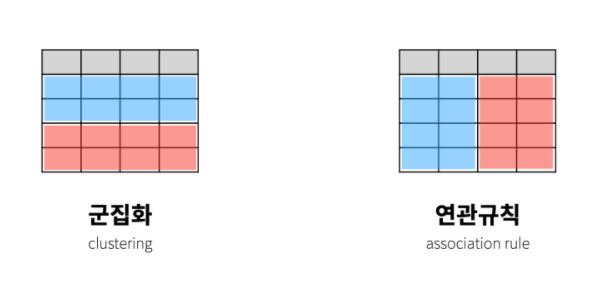
연관규칙은 서로 관련있는 열(특성)을 찾아주는 머신러닝 기법이라고 보면 좋을 것같다.
관측치(행)을 그룹핑 해주는 것-> 군집화
특성(열)을 그룹핑 해주는 것 -> 연관 규칙
비지도 학습(unsupervised learning)
비지도학습은 지도학습과 뭐가 다를까

비지도학습은 데이터들의 성격을 파악하는게 목적이라 데이터만 있으면 되고
지도학습은 과거에 일어났던 원인과 결과를 바탕으로
어떤 원인이 발생했을때 결과를 추측하는 것이 목적이다.
그래서 독립변수와 종속변수가 필요하다.
강화학습(Reinforcement Learning)
강화학습의 핵심은 일단 해보는 것이다.

지도학습은 배움을 통해서 실력을 키운다면
강화학습은 일단 해보면서 경험을 통해서 실력을 키운다
행동을 해보았는데 그 결과가 나한테 유리한 거였으면 상을 주고
불리한 것이었으면 벌을 주는 개념이다(전에 딥러닝 공부했던게 떠오른다...!)
결국 강화학습에서는 더 많은 상을 받을 수 있는 방법을 만드는게 핵심이겠다.
ex) 자율주행자동차도 강화학습을 이용해서 만들어진다. 처음에는 사고치다가 나중에는 주차를 정확하게 함..
머신러닝1 끝!