
지도학습의 빅픽쳐

지도학습을 하기 위해서는...
1. 과거의 데이터가 있어야 함. -> 원인(독립변수)과 결과(종속변수)를 분석해 내야함.
2. 모델의 구조를 만든다.
3. 데이터로 모델을 학습(FIT) 한다.
4. 모델을 이용한다.
Jupyter notebook 을 구글 서비스 내에서 사용할 수 있도록 만든게 Colaboratory
이전에 딥러닝 스터디를 하면서 깔았던 적이 있다. 그러니 패스!
표를 다루는 도구 '판다스'
import pandas as pd 를 해주면
데이터를 불러오고 분류하는 기능을 쓸 수 있게 된다.
실습을 통해 배울 도구들
- 파일 읽어오기 : pd.read_csv('/경로/파일명.csv')
- 모양 확인하기 : print(데이터.shape)
- 칼럼 선택하기 : 데이터[['칼럼명1', '칼럼명2', '칼럼명3']]
- 칼럼 이름 출력하기 : print(데이터.columns)
- 맨 위 5개 관측치 출력하기 : 데이터.head()
csv 라는 건 , 을 통해 칼럼들을 구분함
액셀에서 열면 표의 형태로 보여준다.
실습해보기
첫번째 실습을 해보려고 한다.
데이터를 불러와야 한다.
깃허브에 들어가서 raw 클릭해서 주소를 복사해왔다

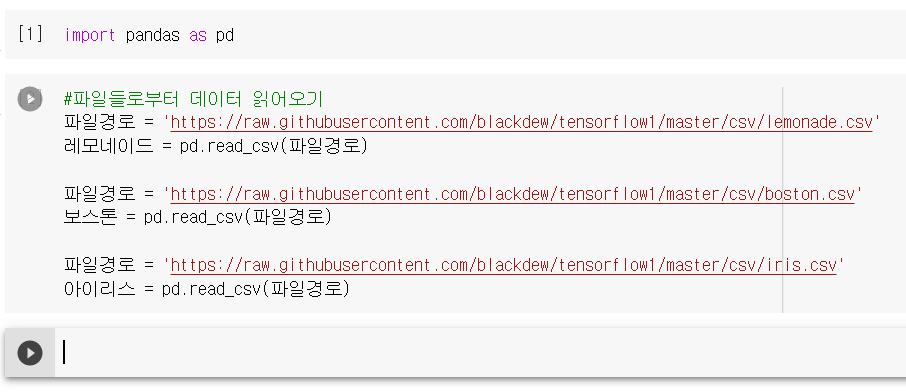
이번엔 데이터가 잘 불러와 졌는지 확인하는 과정을 거쳐보자.

레모네이드 데이터는 칼럼이 2개 로우가 6개 이다.

그래서 다음과 같이 출력이 된다.
칼럼이름을 출력해보자

이제 독립변수와 종속변수로 나누어 줄거다

아래처럼 .head() 를 써주면(이건 판다스에 있는거다)
상위 5개의 데이터를 이렇게 표로 보여준다.

보스톤과 아이리스도 한번 보자

이제 모델을 만들고, 학습시키는 걸 하면 되겠다.
모델의 구조 만들기

데이터를 독립변수와 종속변수로 나누는 것 까지 해봤으니까
레모네이드 판매 예측을 하는 모델의 구조를 한번 만들어 보자
(가장.. 간단한 구조이지만)

각 숫자는 독립변수의 개수와 종속변수의 개수를 의미한다.
mse 의 개념은 이따 알아볼거다.
데이터로 모델을 학습(FIT) 하기

모델학습은 한줄이면 된다.
verbose=0 으로 하면 결과 출력이 안나오게 할수있다(만번은 너무 많아서 저렇게 설정해줬다)
만번 돌렸으니 오차가 적어졌을거다.
이번엔 epochs를 다시 10으로 줄여서 출력을 해보자

오차가 엄청엄청 적어졌다.
모델을 이용해보기

15라는값을 넣었을때 판매량이 몇이 나올지 예측해보라고 했다.
정확히 30은 아니지만, 30에 가까운 값이 나왔다.
Loss

종속변수와 예측을가지고 error 를 구해서
그 에러의 평균을 내면 loss 이다.
예측이 정답을 다 맞추면 loss 가 0에 가까워지겠지.
0에 가까워질수록 학습이 잘 되었다고 할 수있다.

위에는 모델을 가지고 예측한 값,
아래는 정답이다.
참고 : 봉수골 개발자 이선비 유튜브 채널