

이런 데이터가있다고 해보자.
1부터 13까지의 특성들이 14에 영향을 미친다.
독립변수들과 종속변수라고 할 수 있겠다.
이 관계를 식으로 나타내면 다음과 같다. 결과가 정확히 나오진 않지만 비슷한 값을 얻을 수 있다.

이런 복잡한 공식은 머신러닝이 만들어준다.
학습을 잘 시킨다면 더 정확한 값을 얻을 수 있을거다.

레모네이드 판매량 예측 때 했던 순서대로 보스턴 집값도 예측해보자
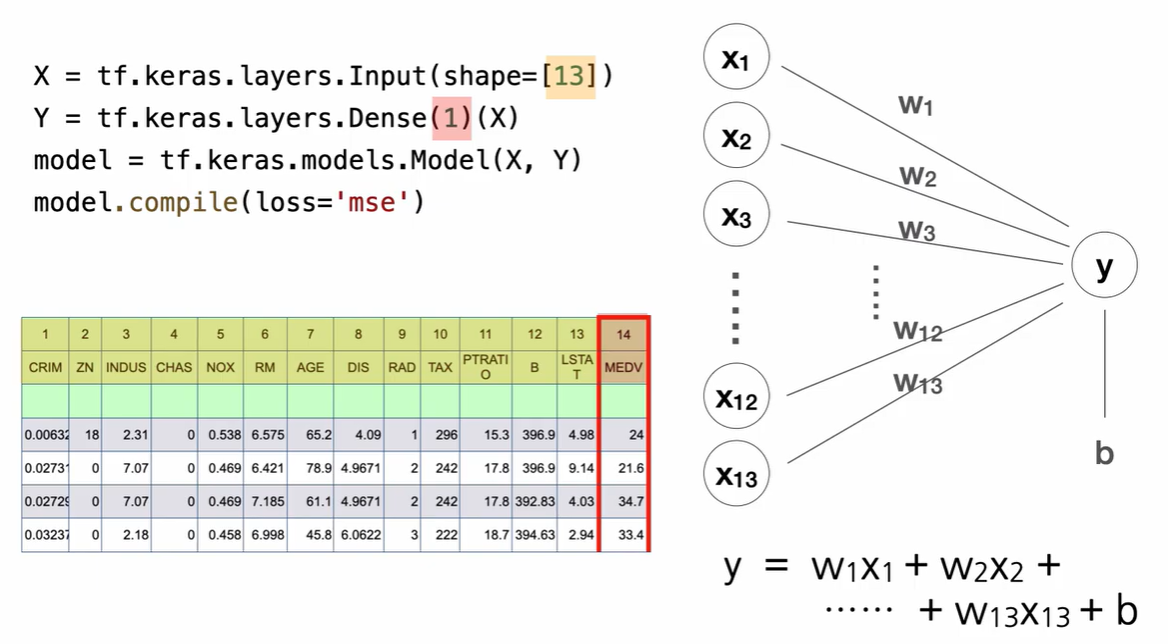
y를 수식으로 나타내면 저렇게 나타낼 수 있는데
이런 모형을 퍼셉트론이라고 하고
각 w들을 가중치 ,
b는 bias (편향)이라고 한다.

만약에 종속변수를 두 개라고 해보자.
그러면 저런 모형이 나올거다.
수식도 두개가 생기겠지.
colab 에 작성을 해보자

텐서플로우랑 판다스를 임포트 해주고
데이터를 가져와 주자.
그다음에 .head() 로 잘 읽어봐졌는지 확인해봤다.

독립변수와 종속변수를 만들고 .shape로 확인한다.
모델의 구조도 만들어 준다.
X에 써있는 shape은 독립변수의 개수
Y에 써있는 숫자는 종속변수의 개수를 써넣어주면 된다.

모델을 1000번 학습시킨다. 이때 출력결과는 너무 기니까 안나오게 해줬다.
그리고 10번 학습을 시킨다. 이건 출력할거다.
loss가 26쯤으로 나온다.
이번엔 모델을 이용해보자.
5부터 10번째 까지의 예측을 출력해보는거다.(슬라이싱 문법을 사용했다.)
그리고 종속변수도 5부터 10까지 출력을 해본다(정답)
꽤 근접한 값들을 예측하고 있다.

다음과 같이 출력을 하면 weights을 확인할수도 있다
데이터는 로컬파일을 이용할수도 있음!
google colab 에 올리고 경로복사하면 됨
참고 : 생활코딩