
learning rate을 조절하는 방법
데이터를 선처리하는 방법
오버피팅을 방지하는 방법에 대해서 이야기 해보자

gradient descent라는 알고리즘을 이용할때
우리는 learning rate라는걸 썼었다.

이렇게 임의의 값으로 지정해 줬었지
그런데 이 learning rate을 잘 정하는 게 중요하다
learning rate은 쉽게 설명하면 gradient descent에서 한발짝(step)이라고 할 수 있다.
이 step이 너무 크면 어떻게 될까?
최저점을 찾아야 하는데 최저점을 지나치면서 왔다갔다 할 것이다.

이런걸 오버슈팅(overshooting)이라고 부른다.
반대로 learning rate가 너무 작다고 생각해보자

cost함수를 한번 실행시켰을 때 너무 변화가 작고 오래걸리면 lr을 다시 정해야 할 것이다.
우리가 가진 환경에 따라 0.01 정도로 일단 설정을 해두고
애가 발산을 한다 -> lr이 너무 크구나
애가 너무 느리다 -> lr이 너무 작구나
정도로 생각하면 좋을 것 같다.

두번째로 얘기할 것은 X 데이터를 선처리해야하는 필요성에 대해서 이다.
우리가 많이 쓰는 gradient descent 를 생각해보자
만약에 weight이 2개라고 생각해보자
그리고 이걸 2차원으로 생각해보자
위에서 내려다 봤다고 생각하면 편하다

저 가운데가 바닥(최저점)이고
어디에서 시작하든 저 바닥에 도달하는게 목표인 것이다.
그런데 예를들어서

x들의 데이터가 좀 저렇게 차이가 심하게 난다면
등고선이 아까처럼 동그랗지 않고 좀 길쭉할 것이다.
이렇게!
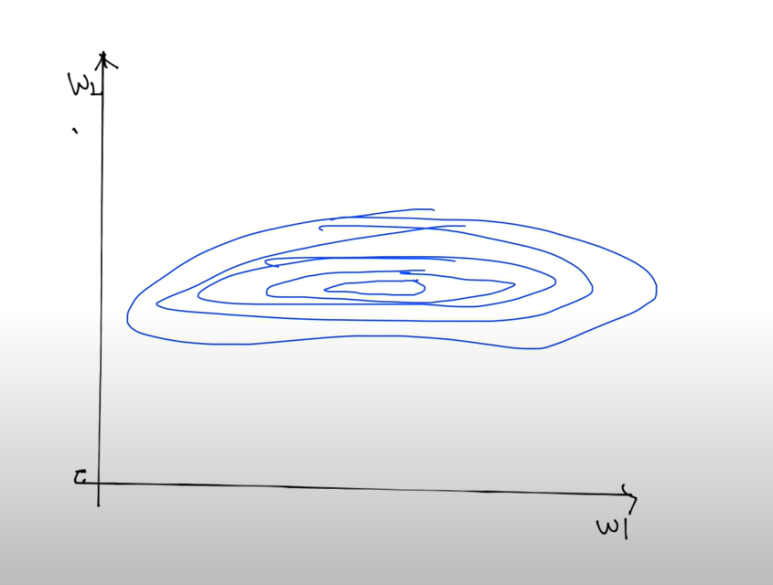
이렇게 데이터 값에 큰 차이가 있을 때 알파 값(lr)을 좀만 크게 잡아도 튕겨져 나갈 수있다
그래서 normalize 라는 과정이 필요하다

zero-centered data는 데이터의 중심이 0으로 가도록 하는 방법이고
normalized data는 지정한 범위 내에 항상 들어가도록 하는 방법이다.
lr을 잘 잡은 것같은데 학습이 안일어나고 cost가 발산하거나 이상한 동작을 보이면
데이터 중에 큰 차이를 보이는게 있는지, 데이터 선처리를 했는지 살펴보면 된다.
하는 방법은 간단하다

standardization 이라는 normalize를 하면 된다
파이썬으로 나타낸다면 아랫줄의 코드로 쓰면 된 것이다.
overfitting에 대해서 알아보자

training data set에 너무 잘 맞는 모델을 만들었다고 하자
근데 이건 test dataset이나 다른 것에 적용할 때에는 잘 안맞을 수도 있다.
예를 들어서 우리가 만드는 모델이 -와 +를 구분하는 프로그램이라고 해보자

저렇게 나눌수도 있는 반면

이렇게도 나눌 수 있을 것이다.
두번째 model2는 실제로 사용할 때 다른 데이터들한테는 정확도가 떨어질 수 있다
이렇게 된 모델을 overfitting이라고 한다.
overfitting 을 해결하는 방법에는 무엇이 있을까?

트레이닝 데이터를 많이 갖고 있거나
feature의 갯수를 (중복제거) 줄이거나
regularization (일반화) 의 방법이 있다
일반화를 한다는게 뭘까?

너무 큰 값을 weight로 갖지 말자는 거다
decision boundary 가 저렇게 구불구불 나타날때가 있다
데이터에 맞추기 위해 (특히 데이터가 너무 차이나는 w때문에) 저렇게 구부러지는 것이 오버피팅이라고 할 수 있는데
이걸 피자는 거다

우리가 cost를 세울때 뒤에 저 수식을 추가해주자
저 앞에 붇는 상수가 regularization strength인데
저 값이 0이면 regularizaiton을 쓰지 않겠다는 거고
저 값이 크면 regularization을 되게 필요해한다는거고
0.01이면 어느정도 필요하다는 거고...
그런 의미!

코드로 나타내면 저러게 되겠다
여기선 regularization strength가 0.001인가보다