

만약에 training set 데이터를 머신러닝 모델에 넣고 학습 시키고
이 학습시킨 모델에 똑같은 training set 데이터를 넣으면 어떻게 될까?
100% 완벽한 답을 낼 수 있을수도 있을 것이다
-> 나쁜 방법,,! 똑같은 문제로 또 시험을 본다고 생각해보자.. 좋은 방법이 아니잖아

그래서 데이터에 한 3:7로 나누고
7은 training set
3은 test set으로 정한다
test set은 냅두고 training set으로만 모델을 만들어서 학습시키고
나중에 test set으로 모델에 줘보는 거다. 잘 실행하는지!
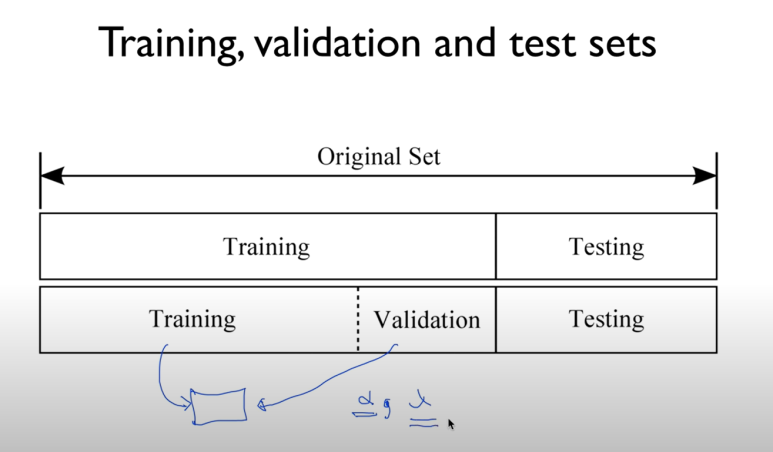
정리해보면 전체 데이터를 original set이라고 보면
training 으로 모델을 만들고
validation 으로 가장 적당한 알파값(learning rate)나 normalize 할때 필요한 상수 값을 찾고(모의시험)
testing set으로 모델을 실행시켜보는 것이다. 잘 작동하나!(한 번만 작동시킨다)
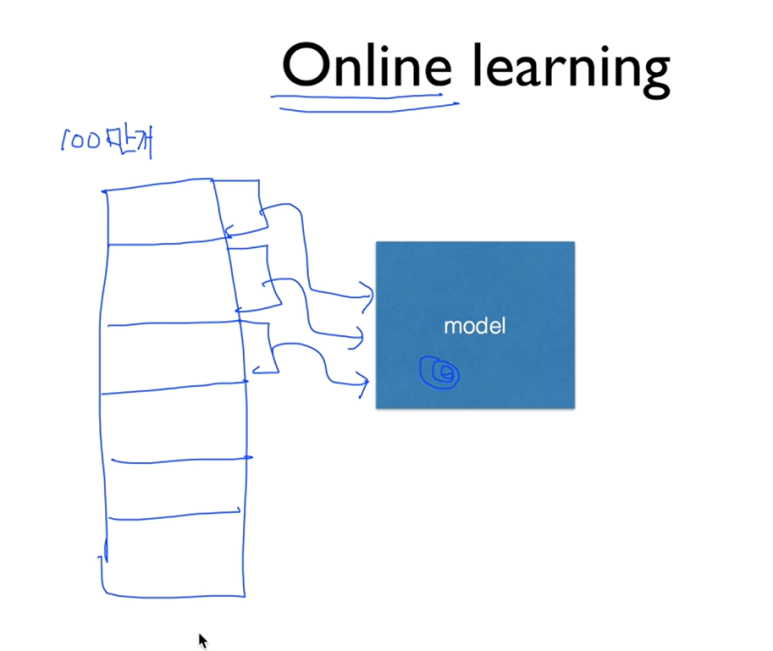
그리고 데이터셋이 너무 많아서 다 올리기 힘들때가 있다
이럴때 쓰는 방법이 online learning이다
training set이 100만개라고 보자. 한번에 넣으려고 하면 힘들거다
그러니 10만개씩 잘라서 학습을 시키는 거다.
이게 좋은 방법인 이유는
나중에 새로운 data set이 들어왔을 때 추가할수 있어서이다

실제 data set을 보자
minist dataset이라고 한다.
사람이 실제로 적어놓은 듯한 숫자글씨를 알아보기 위함이다.
아래 4줄을 보면 images 라는 data set이 있고 (training set)
labels set 이 있다 -> 이거는 실제 답이 되겠다. (test set)

우리가 이제 정확도를 측정하는 것은 간단한 일일 것이다.
label(실제값 Y) 과 Y_hat (예측한 값) 을 비교하면 될 것이다.
실제로 어떻게 측정하는 지는 실습에서 확인해보자
만약에 training set 데이터를 머신러닝 모델에 넣고 학습 시키고
이 학습시킨 모델에 똑같은 training set 데이터를 넣으면 어떻게 될까?
100% 완벽한 답을 낼 수 있을수도 있을 것이다
-> 나쁜 방법,,! 똑같은 문제로 또 시험을 본다고 생각해보자.. 좋은 방법이 아니잖아
그래서 데이터에 한 3:7로 나누고
7은 training set
3은 test set으로 정한다
test set은 냅두고 training set으로만 모델을 만들어서 학습시키고
나중에 test set으로 모델에 줘보는 거다. 잘 실행하는지!
정리해보면 전체 데이터를 original set이라고 보면
training 으로 모델을 만들고
validation 으로 가장 적당한 알파값(learning rate)나 normalize 할때 필요한 상수 값을 찾고(모의시험)
testing set으로 모델을 실행시켜보는 것이다. 잘 작동하나!(한 번만 작동시킨다)
그리고 데이터셋이 너무 많아서 다 올리기 힘들때가 있다
이럴때 쓰는 방법이 online learning이다
training set이 100만개라고 보자. 한번에 넣으려고 하면 힘들거다
그러니 10만개씩 잘라서 학습을 시키는 거다.
이게 좋은 방법인 이유는
나중에 새로운 data set이 들어왔을 때 추가할수 있어서이다
실제 data set을 보자
minist dataset이라고 한다.
사람이 실제로 적어놓은 듯한 숫자글씨를 알아보기 위함이다.
아래 4줄을 보면 images 라는 data set이 있고 (training set)
labels set 이 있다 -> 이거는 실제 답이 되겠다. (test set)
우리가 이제 정확도를 측정하는 것은 간단한 일일 것이다.
label(실제값 Y) 과 Y_hat (예측한 값) 을 비교하면 될 것이다.
실제로 어떻게 측정하는 지는 실습에서 확인해보자